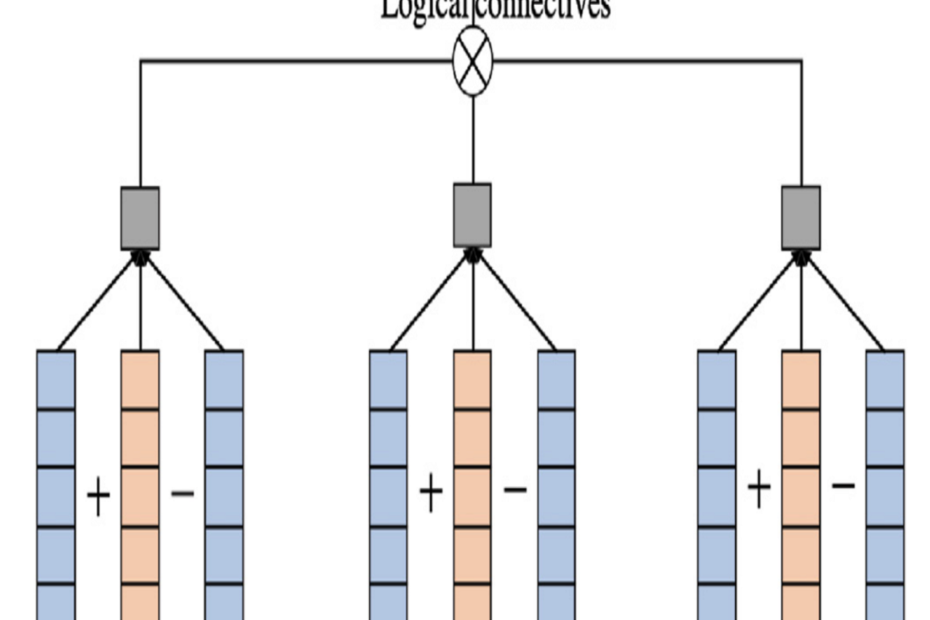
规则增强表示学习的基本思想是不仅在KGs中原始的三元组上学习实体和关系嵌入,而且还学习由一些规则推断出的三元组或基本规则,这也称为符号驱动的神经推理。
规则类型
通常使用的规则大多遵循以下形式:
(x, r, x)
(x, r, y) \( \rightarrow \) (y, r, x)
(x, r, y) \( \wedge \) (y, r, z) \(\rightarrow\) (x, r, z)
(x, r1, y) \(\rightarrow\) (y, r2, x)
(x, r1, y) \( \rightarrow \) (x, r2, y)
(x, r1, y) \( \wedge \) (y, r2, z) \( \rightarrow \) (x, r3, z)
其中,x, y代表实体,r代表关系。
方法类型
有两种主要的方法。第一种在开始时推断规则一次,并在学习过程中保持规则不变。这些规则将影响嵌入学习。
第二个还根据每次迭代时更新的嵌入来推断新规则,从而推断新规则并迭代推导出新的三元组。
经典方法
例如,KALE处理两种类型的规则:
(x, r1, y) \( \rightarrow \) (x, r2, y)
(x, r1, y) \( \wedge \) (y, r2, z) \( \rightarrow \) (x, r3, z)
KALE找到上述两类规则的所有基本规则,为每个基本规则分配一个分数,表示满足基本规则的可能性,最后在原始三元组的训练集上学习实体和关系嵌入和基本规则。
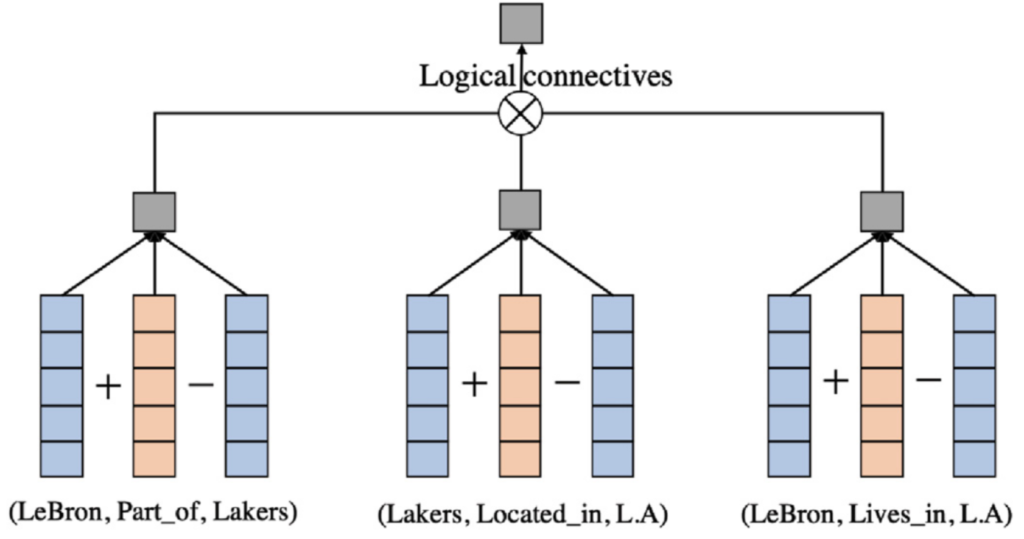
在KALE的基础上,RUGE将规则的一轮注入变为迭代的方式。RUGE不是直接将基本规则推出的结果视为正例,而是将某些规则派生的三元组作为未标记的三元组注入,以更新实体/关系嵌入。由于未标记的三元组不一定是真的,RUGE根据当前嵌入预测每个未标记的三元组的概率。然后基于标记和未标记的三元组更新嵌入。
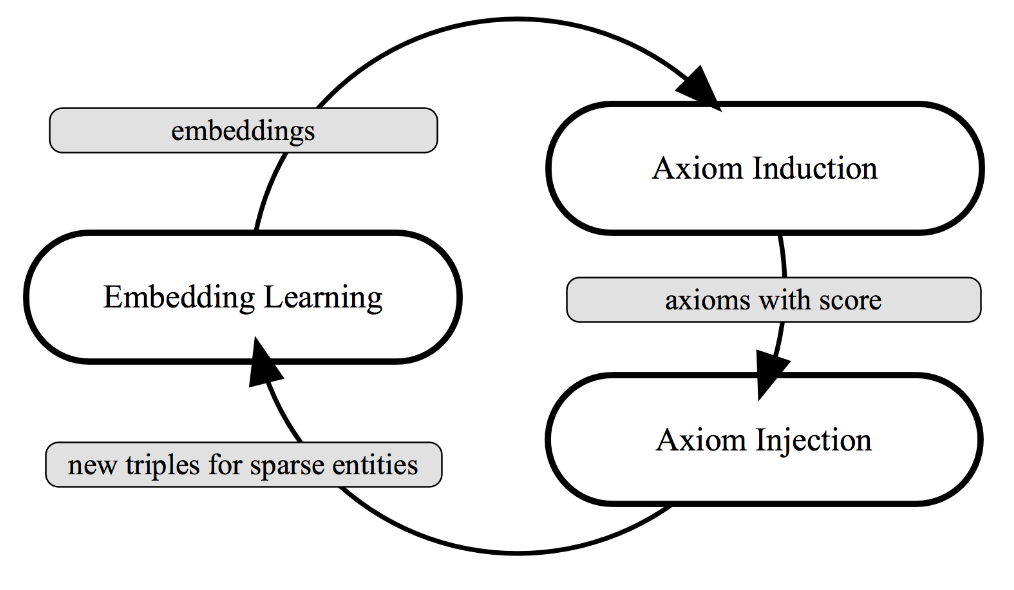
IterE还根据每次迭代更新的嵌入推断新规则,能够推断新规则,并根据实体和关系嵌入从规则中派生出新的三元组,然后根据扩展的三元组更新这些嵌入。这两个过程是迭代执行的。
[1] Jointly Embedding Knowledge Graphs and Logical Rules.
[2] Knowledge graph embedding with iterative guidance from soft rules
[3] [Iteratively Learning Embeddings and Rules for Knowledge Graph Reasoning](