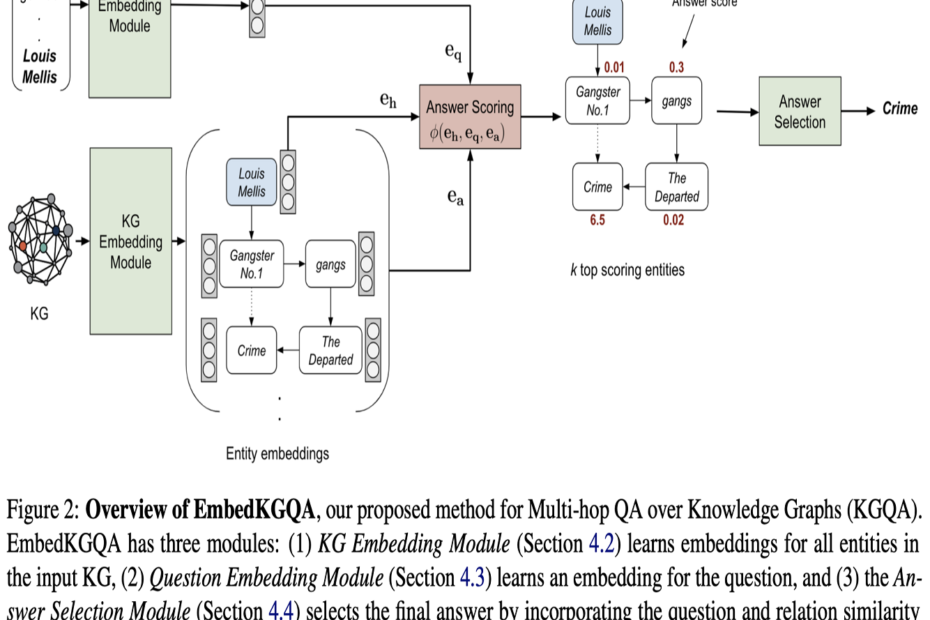
知识图谱(KG)由大量的实体以及实体间的关系组成。基于知识图谱的问答(KGQA),其目标是回答在给定知识图谱上提出的自然语言查询。
通过链接预测来减缓知识图谱的稀疏性,知识图谱嵌入方法可以有效地支持多跳的知识图谱问答。在ACL 2020接收的一篇论文Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings中,研究人员提出了EmbedKGQA,利用知识图谱嵌入可以完成链接预测特性,在不使用任何额外数据的情况下缓解KG不完整问题,从而克服现有多跳知识图谱问答方法中有限邻域大小的缺陷。
在这里,我们使用NeuralKG来完成EmbedKGQA的嵌入训练的步骤,并展示了基于NeuralKG的EmbedKGQA的整个训练过程。
数据处理
- 我们从EmbedKGQA的github代码仓库中下载源代码(我们使用编号为c101d58的提交代码),并从README.md中提供的google drive链接下载data.zip。
- 我们把文件夹
data放入EmbedKGQA-master - 我们将
data/MetaQA_half中的数据格式(我们以MetaQA_half为例)转换为NeuralKG的数据格式。具体来说,在原始的entities.dict和relations.dict# relations.dict directed_by 0 directed_by_reverse 1 has_genre 2 has_genre_reverse 3所以我们将索引编号处理后,放在第一列如下
# relations.dict 0 directed_by 1 directed_by_reverse 2 has_genre 3 has_genre_reverse - 此外,MetaQA_half中的一些实体由空格符号组成,且原始的
train.txt、valid.txt和test.txt中三元组的间隔是制表符。为了符合NeuralKG的读取格式,我们将实体中的空格符号替换为_
嵌入训练
- 我们把处理好的MetaQA_half数据集放到NeuralKG代码的
dataset - 我们编写以下脚本,并运行这个脚本(这里提供的可能并不是最优的超参数)。
MODEL_NAME=ComplEx DATASET_NAME=MetaQA_half DATA_PATH=$DATA_DIR/$DATASET_NAME LITMODEL_NAME=KGELitModel MAX_EPOCHS=1000 EMB_DIM=200 LOSS=Adv_Loss ADV_TEMP=1.0 TRAIN_BS=1024 EVAL_BS=16 NUM_NEG=64 MARGIN=200.0 LR=5e-3 REGULARIZATION=1e-5 CHECK_PER_EPOCH=20 NUM_WORKERS=16 GPU=3 CUDA_VISIBLE_DEVICES=$GPU python -u src/main.py \ --model_name $MODEL_NAME \ --dataset_name $DATASET_NAME \ --data_path $DATA_PATH \ --litmodel_name $LITMODEL_NAME \ --max_epochs $MAX_EPOCHS \ --emb_dim $EMB_DIM \ --loss $LOSS \ --adv_temp $ADV_TEMP \ --train_bs $TRAIN_BS \ --eval_bs $EVAL_BS \ --num_neg $NUM_NEG \ --margin $MARGIN \ --lr $LR \ --regularization $REGULARIZATION \ --check_per_epoch $CHECK_PER_EPOCH \ --num_workers $NUM_WORKERS \ --save_config \ - 最后,我们在
./output/link_prediction/MetaQA_half/ComplEximport torch import numpy as np model = torch.load('epoch=xxx-Eval|mrr=x.xxx.ckpt') rel_emb = model['state_dict']['model.rel_emb.weight'] ent_emb = model['state_dict']['model.ent_emb.weight'] np.save('R.npy', rel_emb.cpu().numpy()) np.save('E.npy', ent_emb.cpu().numpy())
运行EmbedKGQA
- 在EmbedKGQA的代码中,我们替换其
./KGQA/LSTM/main.pyhops = args.hops if hops in ['1', '2', '3']: hops = hops + 'hop' if args.kg_type == 'half': data_path = '../../data/QA_data/MetaQA/qa_train_' + hops + '_half.txt' else: data_path = '../../data/QA_data/MetaQA/qa_train_' + hops + '.txt' print('Train file is ', data_path) hops_without_old = hops.replace('_old', '') valid_data_path = '../../data/QA_data/MetaQA/qa_dev_' + hops_without_old + '.txt' test_data_path = '../../data/QA_data/MetaQA/qa_test_' + hops_without_old + '.txt' model_name = args.model kg_type = args.kg_type print('KG type is', kg_type) # embedding_folder = '../../pretrained_models/embeddings/' + model_name + '_MetaQA_' + kg_type embedding_folder = '../../embedding' entity_embedding_path = embedding_folder + '/E.npy' relation_embedding_path = embedding_folder + '/R.npy' entity_dict = embedding_folder + '/entities.dict' relation_dict = embedding_folder + '/relations.dict' # w_matrix = embedding_folder + '/W.npy' w_matrix = None bn_list = [] # for i in range(3): # bn = np.load(embedding_folder + '/bn' + str(i) + '.npy', allow_pickle=True) # bn_list.append(bn.item()) - 我们注释掉
./KGQA/LSTM/model.py - 运行命令行为
python main.py --mode train --relation_dim 200 --hidden_dim 256 \ --gpu 2 --freeze 0 --batch_size 128 --validate_every 5 --hops 2 --lr 0.0005 --entdrop 0.1 --reldrop 0.2 --scoredrop 0.2 \ --decay 1.0 --model ComplEx --patience 5 --ls 0.0 --kg_type half最终我们获得测试结果为83.85。